컬렉션 설정¶
1. 메뉴 개요¶
검색엔진에 색인할 데이터 묶음(컬렉션)을 정의·관리하고, 수집(Spider)과 색인(Indexer)을 설정·실행하는 핵심 운영 메뉴입니다. 컬렉션을 추가하고, 원본 데이터(DB 또는 웹) 연결을 설정한 뒤, 수집·색인을 실행해야 비로소 검색 결과에 노출됩니다.
2. 메뉴 위치¶
[좌측 메뉴바] > [시스템 설정] > [컬렉션 관리] > [컬렉션 설정]
URL: /system/collection/collection-status
3. 화면 구성¶
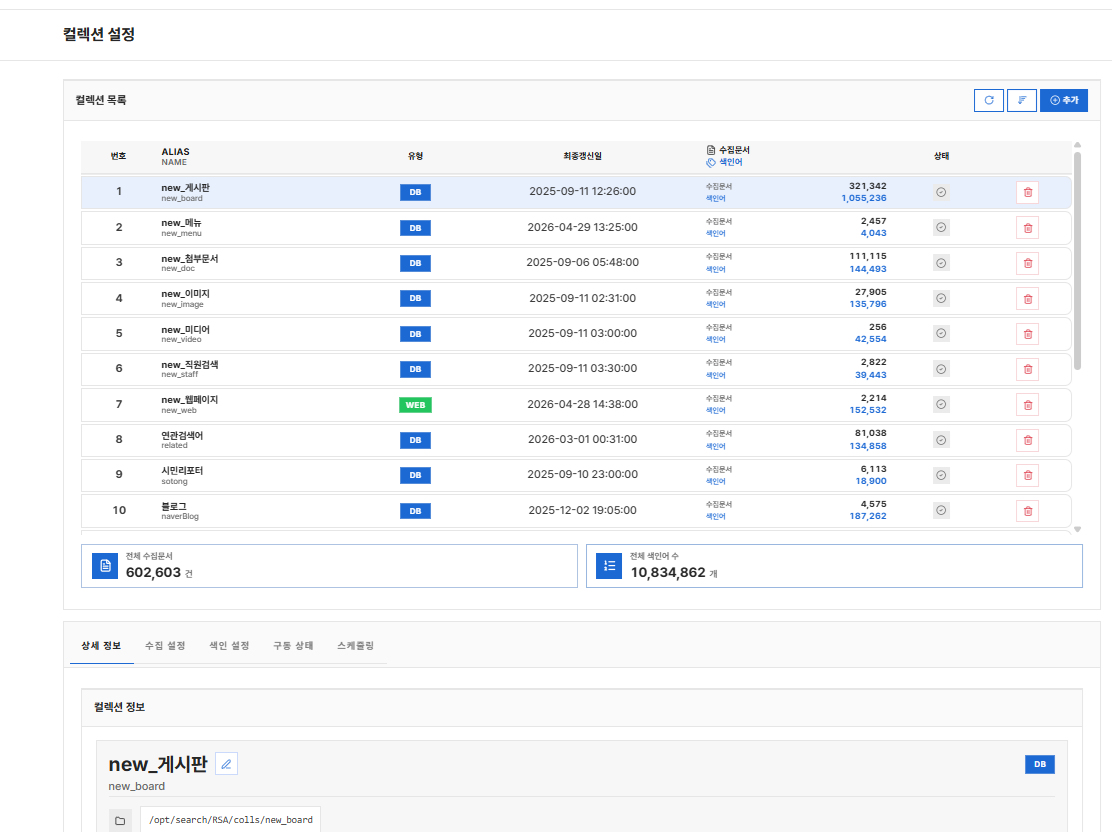
| 번호 | 영역 | 설명 |
|---|---|---|
| ① | 컬렉션 목록 카드 | 등록된 컬렉션 카드 (ALIAS/NAME, 유형(DB/WEB), 최종갱신일, 수집 문서·색인어 수, 상태) |
| ② | [추가] / [동기화] / [정렬] | 신규 컬렉션 추가, 엔진과 동기화, 정렬 변경 |
| ③ | 전체 통계 | 모든 컬렉션의 수집 문서·색인어 합계 |
| ④ | 상세 영역 (행 클릭 시) | 5개 탭 - 상세 정보 / 수집 설정 / 색인 설정 / 구동 상태 / 스케줄링 |
상세 영역의 5개 탭¶
| 탭 | 무엇을 보고/하는가 |
|---|---|
| 상세 정보 | 컬렉션의 ALIAS/NAME, 로컬 경로, 레코드·색인어 수, 생성·갱신 일자 |
| 수집 설정 | 원본 연결과 수집 규칙. DB 컬렉션은 DB 연결·테이블·메타필드, WEB 컬렉션은 시드 URL·영역 패턴·인증 |
| 색인 설정 | 어떤 필드를 색인할지·정렬·파티션 |
| 구동 상태 | 수집기·색인기 실행, 진행 상태와 로그, 전체 실행(수집 → 색인 → 포스팅) |
| 스케줄링 | 이 컬렉션의 자동 실행 스케줄 (자세한 절차는 스케쥴링 관리) |
4. 주요 작업 방법¶
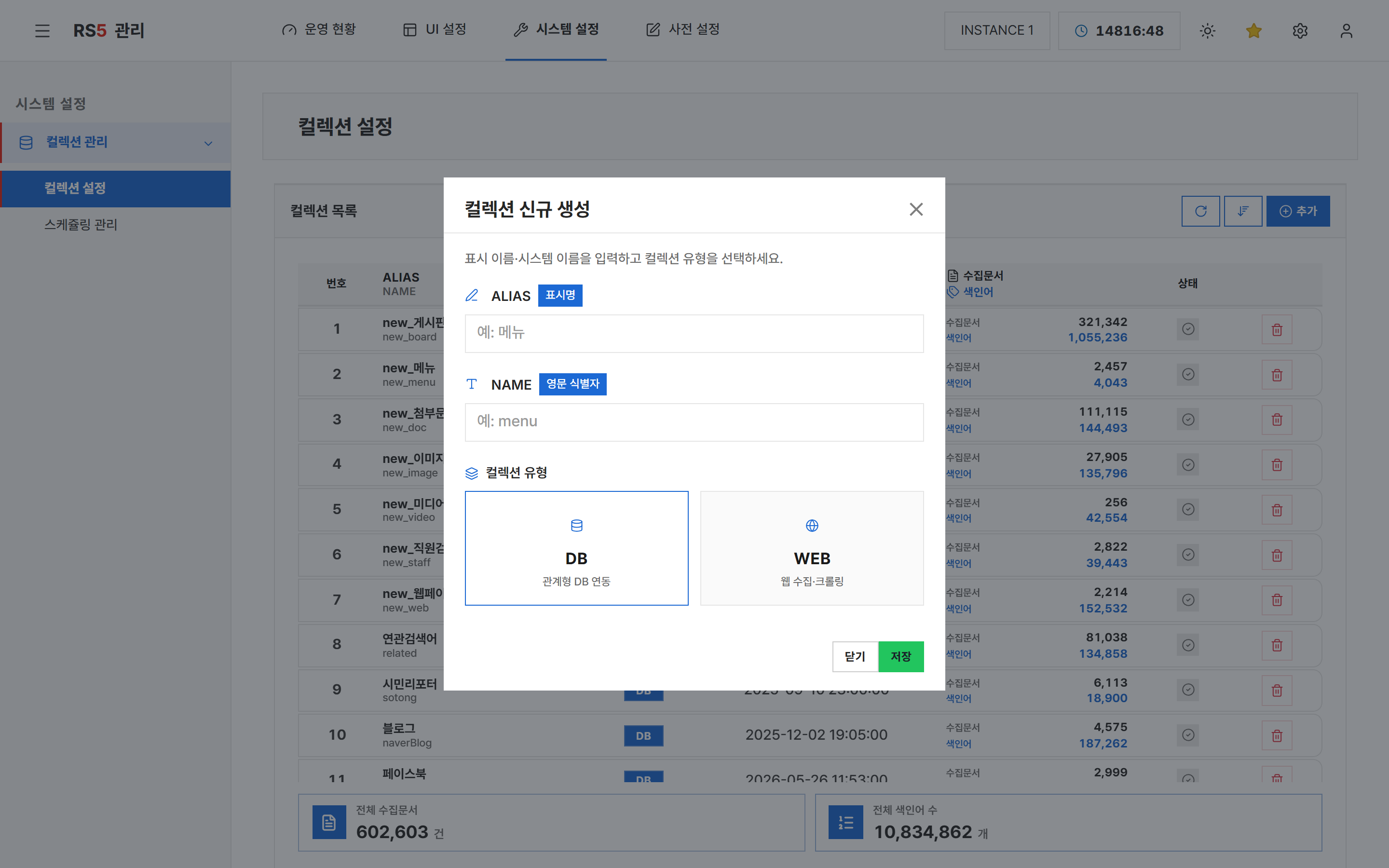
4.1 신규 컬렉션 추가¶
- ② [추가] 버튼을 클릭합니다.
- 모달에 다음을 입력합니다:
- ALIAS — 화면에 표시될 이름 (한글·영문 자유)
- NAME — 시스템 내부 식별자 (영문자로 시작, 영문·숫자·언더스코어만 허용)
- 유형 — DB 또는 WEB
- [저장]을 클릭합니다.
- 목록에 추가된 컬렉션을 클릭해서 수집·색인 설정으로 진행합니다.
4.2 수집 설정 — DB 컬렉션¶
[수집 설정] 탭은 5개의 접고 펼 수 있는 카드로 구성됩니다. 위에서 아래로 순서대로 작성하면 됩니다.
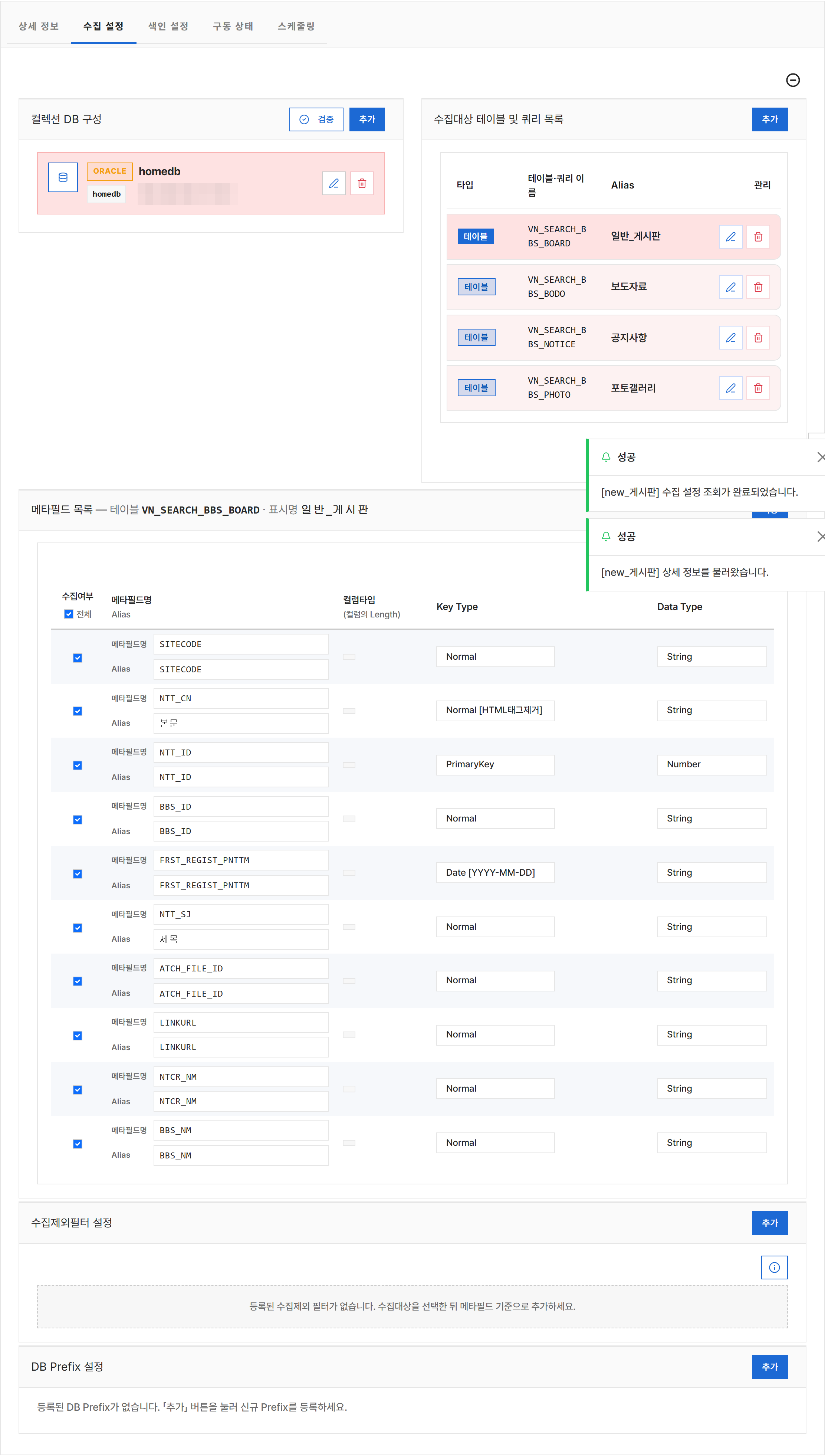
① DB 연결 정보 카드¶
수집할 데이터가 어느 데이터베이스에 있는지를 등록합니다.
| 입력 항목 | 의미 / 입력 예 |
|---|---|
| DB 종류 | MySQL · Oracle · PostgreSQL · MSSQL · Tibero 중 선택 |
| JDBC URL | jdbc:mysql://10.0.0.1:3306/rs5 같은 연결 문자열 |
| 사용자 / 비밀번호 | DB 접속 계정 |
| 별칭(Alias) | 화면에서 구분하기 위한 표시 이름 |
작업 순서: 1. [추가] 또는 기존 행 [수정]을 클릭해 모달을 엽니다. 2. 값을 입력하고 [연결 테스트]를 눌러 접속 가능 여부를 확인합니다. 3. 연결이 성공하면 [저장]을 클릭합니다.
② 수집 대상 (테이블/쿼리) 카드¶
DB 안에서 어느 데이터를 가져올지를 정합니다.
| 입력 항목 | 의미 |
|---|---|
| 테이블 또는 쿼리 | 수집할 단일 테이블명, 또는 직접 작성한 SELECT 쿼리 |
| 별칭(Alias) | 화면 표시용 이름 |
| WHERE 조건 | 특정 행만 수집하기 위한 필터 (예: status = 'PUBLISHED') |
대표 시나리오:
- 게시판 전체 → 테이블명 tb_board
- 공개 글만 → 쿼리 SELECT * FROM tb_board WHERE is_public = 1
③ 메타 필드 카드¶
선택한 테이블·쿼리의 컬럼 중 어느 컬럼을 어떻게 수집할지 매핑합니다.
| 입력 항목 | 의미 |
|---|---|
| 수집 여부 체크 | 해당 컬럼을 수집에 포함할지 |
| 데이터 타입 | TEXT / NUMBER / DATE 등 |
| 키 타입 | 이 컬럼이 문서 식별자(PK) 역할인지 |
| 파일 키 | 이 컬럼 값이 첨부파일 경로일 때 사용 |
상단의 [전체 선택] 체크박스로 모든 컬럼을 일괄 수집 대상으로 지정할 수 있습니다.
④ 제외 필터 카드¶
특정 값을 가진 행을 수집에서 제외합니다 (블랙리스트).
| 입력 항목 | 의미 |
|---|---|
| 필드명 | 검사할 컬럼 |
| 연산자 | =, !=, LIKE, NOT LIKE 등 |
| 값 패턴 | 제외할 값 (예: 삭제됨%) |
예: status LIKE 'DEL%' 행은 수집 제외.
⑤ DB Prefix 카드 (첨부파일 경로 보정)¶
DB에 저장된 첨부파일 경로가 실제 파일 시스템 위치와 다를 때, 테이블별로 경로 접두어(Prefix)를 보정하는 카드입니다. 색인 시 이 prefix가 자동으로 첨부파일 경로 앞에 붙어 실제 파일을 정확히 찾아냅니다.
| 입력 항목 | 의미 |
|---|---|
| 테이블명 | prefix를 적용할 대상 테이블 |
| 경로(Path) | 첨부파일 경로 앞에 덧붙일 실제 디렉토리 |
대표 시나리오:
- DB에 첨부파일 경로가
/upload/2026/file.pdf로 저장돼 있는데, 실제 파일은 NAS의/mnt/share/board/upload/2026/file.pdf에 있을 때 → 테이블명tb_board, 경로/mnt/share/board등록 - 운영 서버 이전으로 첨부파일 마운트 경로가 바뀌었지만 DB의 기존 값은 그대로일 때
- 색인 결과 첨부파일이 "파일을 찾을 수 없음"으로 나오는 경우 1순위 점검 항목
작업 순서:
- [추가] 버튼으로 새 행을 만듭니다.
- 테이블명과 보정 경로를 입력합니다.
- 행 우측 [저장] 아이콘을 클릭합니다.
prefix를 잘못 입력하면 첨부파일 미리보기·다운로드가 모두 실패하므로, 등록 후 반드시 색인을 다시 돌려 검색 결과에서 첨부파일이 정상 열리는지 확인하세요.
4.3 수집 설정 — WEB 컬렉션¶
[수집 설정] 탭은 4개의 접고 펼 수 있는 카드로 구성됩니다.
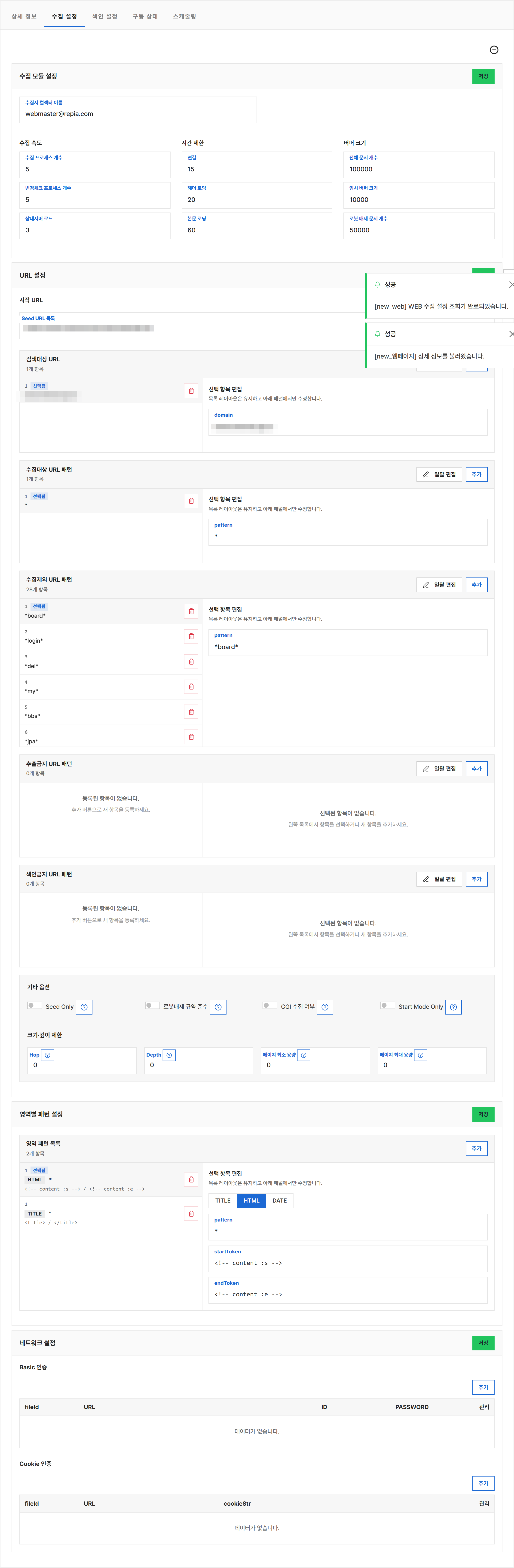
① 수집기 (Collector) 카드¶
웹 크롤러의 동작 방식을 결정합니다.
| 입력 항목 | 의미 |
|---|---|
| Seed Only | 시드 URL 목록만 수집하고 인링크는 따라가지 않음 |
| robots.txt 준수 | 상대 사이트의 robots.txt 정책을 따름 (국제 검색 규약) |
| CGI 수집 여부 | 동적 페이지(.cgi, .do 등) 수집 여부 |
| Start Mode Only | 매번 처음 수집하는 것처럼 동작 (수집 일자 매번 갱신) |
| Hop | 인링크를 따라가는 반복 횟수 제한 (무한 크롤링 방지) |
| Depth | URL의 / 깊이 제한 (예: 3이면 a/b/c까지만) |
| Min Page Size | 이 크기 미만의 페이지는 무효 응답으로 간주하고 버림 |
| Max Page Size | 이 크기를 넘는 페이지는 수집하지 않음 |
각 항목은 입력 옆 ? 아이콘으로 상세 설명을 볼 수 있습니다.
② URL 카드¶
크롤링 시작점과 범위를 정의합니다.
| 입력 항목 | 의미 |
|---|---|
| Seed URL | 크롤링 시작 URL 목록 (한 줄에 하나씩) |
| 범위(Scope) | 수집 허용 도메인. 시드와 다른 도메인의 링크는 무시 |
| URL 패턴 | 포함 / 제외할 URL 정규식 패턴 (예: 게시판 글만, /admin/ 제외) |
③ 영역 (Area Pattern) 카드¶
HTML 페이지에서 어느 부분을 수집해 색인할지를 패턴으로 지정합니다.
| 입력 항목 | 의미 |
|---|---|
| 영역 타입 | TITLE (제목) / HTML (본문) / DATE (작성일) |
| 패턴 | 추출 정규식 또는 시작·끝 토큰 |
| 시작 토큰 / 끝 토큰 | 시작 토큰부터 끝 토큰 사이의 텍스트만 추출 |
예: 게시판 글의 본문 영역만 추출하려면 본문 시작/끝 HTML 태그를 토큰으로 지정.
④ 네트워크 (인증) 카드¶
비공개 페이지를 크롤링해야 할 때 인증 정보를 등록합니다.
| 입력 항목 | 의미 |
|---|---|
| HTTP Basic | URL 패턴 + 사용자 + 비밀번호 |
| 쿠키 | URL 패턴 + 쿠키 문자열 (예: JSESSIONID=...) |
공개 사이트만 수집할 때는 비워 둡니다.
4.4 색인 설정¶
수집된 데이터 중 어떤 필드를 색인할지, 정렬·파티션은 어떻게 할지를 정합니다. DB·WEB 공통으로 다음 항목을 다룹니다.
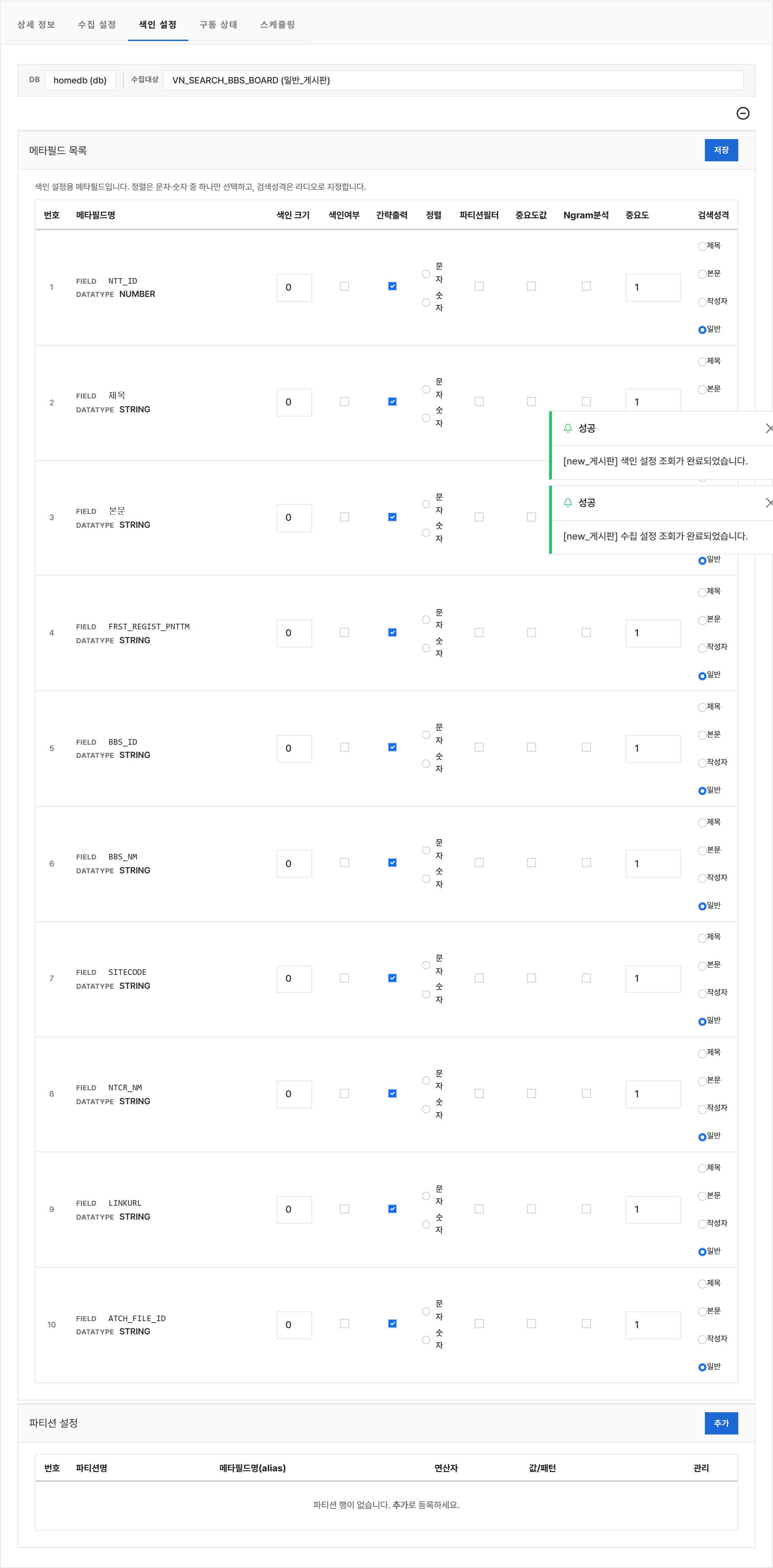
메타 필드 표¶
수집된 컬럼·영역마다 색인 옵션을 체크합니다.
| 옵션 | 의미 |
|---|---|
| Indexed (색인) | 이 필드를 검색 가능하게 색인 |
| Display (표시) | 검색 결과 화면에 노출할 필드 |
| WID (문서 식별자) | 이 필드 값을 문서 고유 식별자로 사용 (보통 PK 컬럼) |
| Partition Filter | 이 필드 값으로 파티션 분할/필터 |
| Ngram | 부분 일치 검색을 위한 N-gram 색인 (예: "사과파이"가 "파이"로도 검색되게) |
| Sort: String | 문자열로 정렬 가능하게 |
| Sort: Number | 숫자로 정렬 가능하게 |
검색 역할 (Search Role)¶
각 필드의 의미를 지정해 검색·하이라이트에 활용합니다.
| 역할 | 용도 |
|---|---|
| NORMAL | 일반 필드 (기본값) |
| TITLE | 제목 — 검색 가중치 ↑, 결과 화면 제목 영역 |
| BODY | 본문 — 검색 가중치 보통, 결과 화면 본문 영역 |
| WRITER | 작성자 |
파티션¶
데이터가 많을 때 색인을 여러 묶음으로 나눠 성능을 확보합니다.
- [파티션 추가] 버튼 클릭
- 파티션 이름과 조건(예: 카테고리=1) 입력
- [저장] 클릭
파티션을 사용하면 검색 시 특정 묶음만 조회하거나, 색인을 분산 갱신할 수 있습니다.
4.5 수집·색인 실행¶
설정이 완료되면 [구동 상태] 탭에서 실제 실행합니다.
| 버튼 | 동작 |
|---|---|
| 수집 | 원본 데이터를 가져와 중간 저장소에 기록 |
| 색인 | 중간 저장소 데이터를 검색엔진에 색인 |
| 전체 실행 | 수집 → 색인 → 포스팅 순으로 한 번에 실행 |
| 중지 | 실행 중인 작업을 중단 |
실행 중 로그와 진행 상태가 실시간으로 표시됩니다.
4.6 컬렉션 삭제¶
- ① 목록 카드의 행 우측 [삭제] 아이콘을 클릭합니다.
- 확인 창에서 [삭제]를 선택합니다.
5. 🚨 주의사항¶
컬렉션 삭제는 복구 불가
삭제하면 검색엔진의 색인 파일과 메타데이터가 함께 정리됩니다. 한 번 삭제된 컬렉션은 복구할 수 없습니다.
운영 시간대의 전체 실행은 트래픽 영향
전체 재수집은 일시적으로 검색 결과 누락이나 색인 부하를 유발할 수 있습니다. 가능하면 트래픽이 적은 야간(00~06시)에 수행하세요.
NAME 규칙
NAME은 영문자로 시작하고, 영문·숫자·언더스코어(_)만 허용됩니다. 한 번 만든 NAME과 유형은 변경할 수 없습니다.
색인 옵션을 켜면 색인 크기가 증가
Indexed·Ngram을 많은 필드에 켜면 색인 크기가 커지고 색인 속도가 느려집니다. 실제 검색에 필요한 필드만 색인하세요.
- 동일 컬렉션을 동시에 실행하는 시도는 차단됩니다 — 이미 실행 중이면 새 실행 요청이 거절됩니다.
- 컬렉션을 검색 결과에 노출하려면 검색 메뉴 및 섹션에서 섹션에 연결해야 합니다.
- 수집 설정·색인 설정을 변경한 후에는 반드시 [구동 상태] 탭에서 [전체 실행]을 한 번 더 돌려야 변경이 반영됩니다.